ABBYY FineReader for ScanSnap的光学字符识别(OCR)功能
本节对ABBYY FineReader for ScanSnap的光学字符识别(OCR)功能做出说明。
ABBYY FineReader for ScanSnap的概要
ABBYY FineReader for ScanSnap为只对ScanSnap使用的应用程序。该程序只能对由ScanSnap创建的PDF文件进行文本识别。无法文本识别使用Adobe Acrobat或其他应用程序创建的文件。
OCR功能的特点
OCR功能具有如下特点。进行文本识别之前,依照如下指导检查文档是否适用于文本识别:
| 应用程序 | 适用于文本识别 | 不适用于文本识别 |
|---|---|---|
| ABBYY Scan to Word | 只有一、二栏的简单页面布局的文档 |
带有混合的图、表和文本的复杂页面布局的文档(比如小册子、杂志和新闻) |
| ABBYY Scan to Excel(R) | 包含简易表格,且表格的各边界线皆与边框相连的文档。 |
包含以下内容的文档:
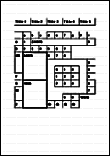 |
| ABBYY Scan to PowerPoint(R) | 含有文本和简单图表/表格背后为白色或浅淡黑白背景的文档 |
 |
无法按原始文档重现的参数
下面的参数或许可被重现为与原始文档中的相同。推荐在Word、Excel或PowerPoint中检查文本识别的结果,如有需要,请编辑数据。
- 字符字体和大小
- 字符和行距
- 下划线、粗体和斜体字符
- 上标/下标
无法正确识别的文档
下面的文档类型可能不会被正确识别。通过调整色彩模式或提高分辨率,可能会得到较好的文本识别结果。
- 含有手写字符的文档
- 含有小字符的文档(小于10号字体)
- 倾斜的文档
- 以非指定语言写成的文档
- 在不均匀色彩的背景上写有字符的文档
示例: 字符底纹 - 有很多装饰字符的文档
示例: 雕饰字符(突出/边框) - 字符带有花纹背景的文档
示例: 字符遮盖了插图和图表 - 含有很多下划线或粗体字符的文档
- 含有大量图像噪音的复杂页面布局的文档
(对这类文档的文本识别,可能会额外花费些时间。)
其他注意事项
- 当转换文档为Excel文件时,如果识别结果超过了65,536行,则不会保存超出的。
- 当转换文档为Excel文件时,有关整个文档的页面布局信息、图表的长度、宽度则不会复制。只有表格和字符会被重现。
- 转换的PowerPoint文档不会有原始的背景颜色和图案。
- 无法正确识别上下颠倒或横向的文档。使用旋转扫描图像到正确方向,或将文档按正确方向放置。
- 如果启用了降低背面透过,则识别率可能会变低。那时,请按下步骤禁用该功能。
按住键盘上的[control]键的同时单击Dock中的ScanSnap Manager图标
 ,然后从ScanSnap Manager菜单中单击[设置] → [正在扫描]选项卡 → [选项]按钮以显示[扫描模式选项]窗口。然后,取消选择[扫描模式选项]复选框(对于SV600,[减少背面透过]复选框位于[扫描模式选项]窗口的[图像画质]选项卡中)。
,然后从ScanSnap Manager菜单中单击[设置] → [正在扫描]选项卡 → [选项]按钮以显示[扫描模式选项]窗口。然后,取消选择[扫描模式选项]复选框(对于SV600,[减少背面透过]复选框位于[扫描模式选项]窗口的[图像画质]选项卡中)。